深度学习视频理解02
- 计算机科学
- 2023-10-16
- 211热度
- 0评论
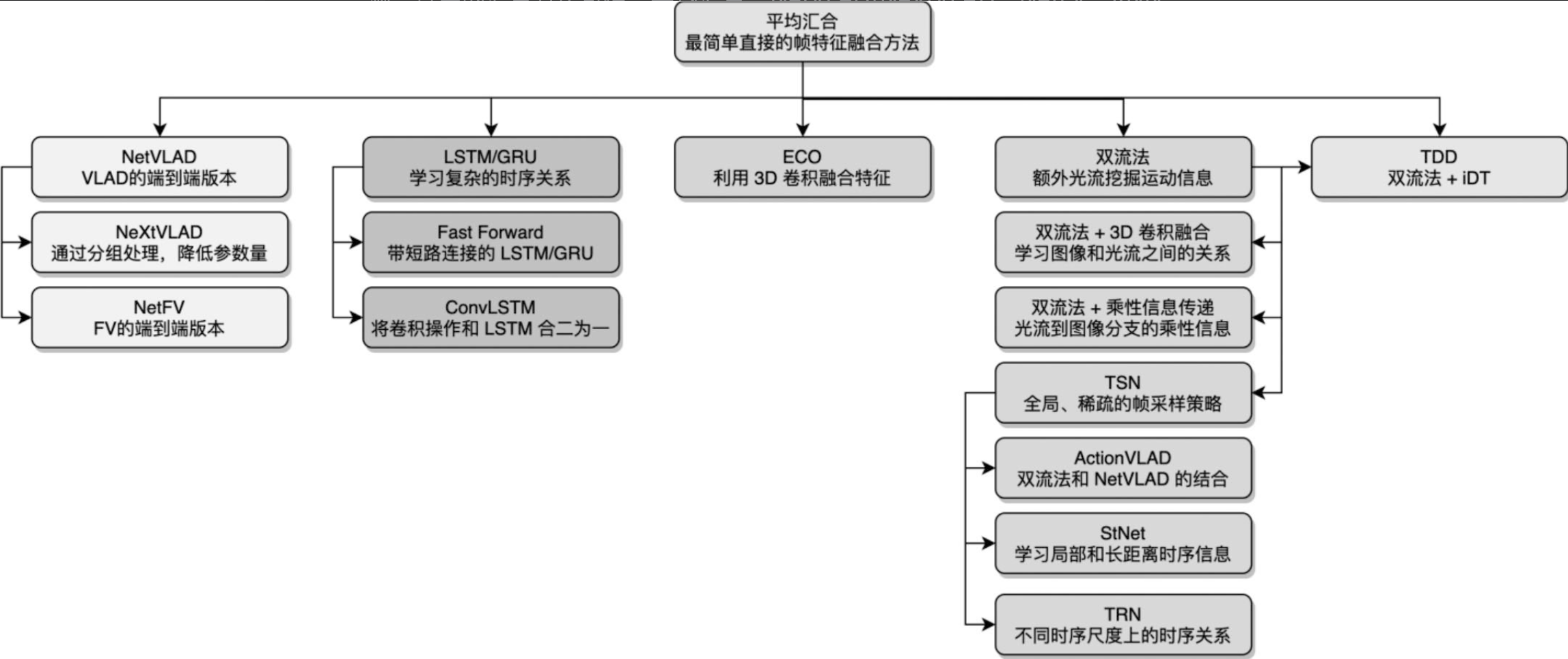
基于2D卷积的动作识别
RNN、LSTM和GRU结构 略去
1、平均汇合(Average Pooling)
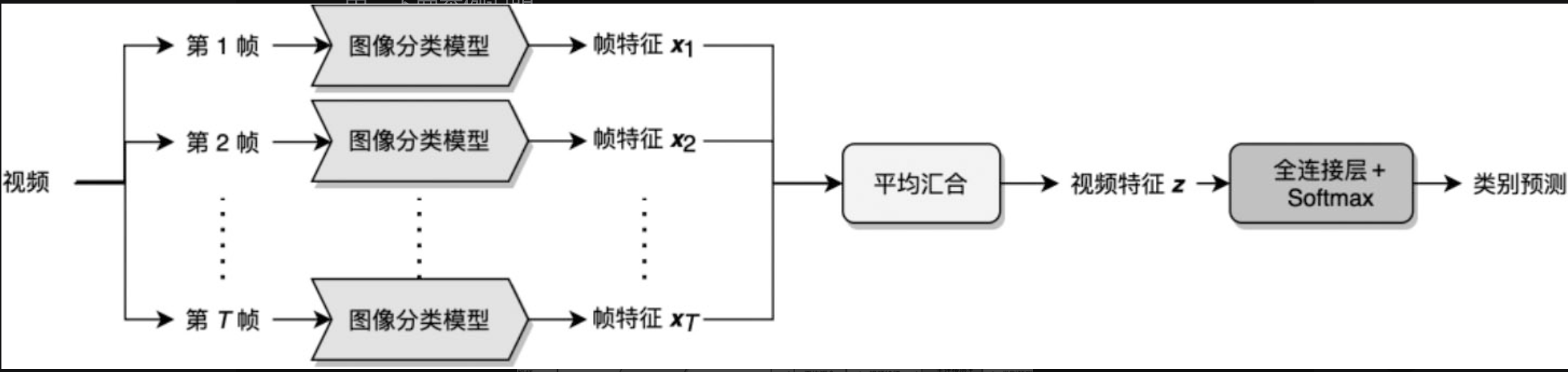
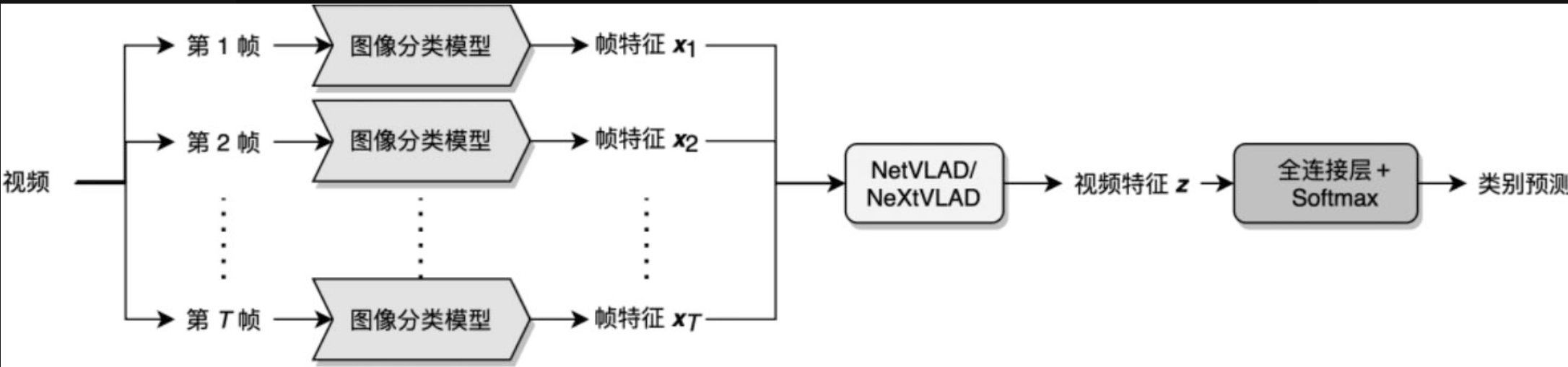
在帧特征层面进行汇合得到视频级别特征Z,为视频内容的向量化表示称视频Embedding
每帧图像的特征对整体的共享是相同的
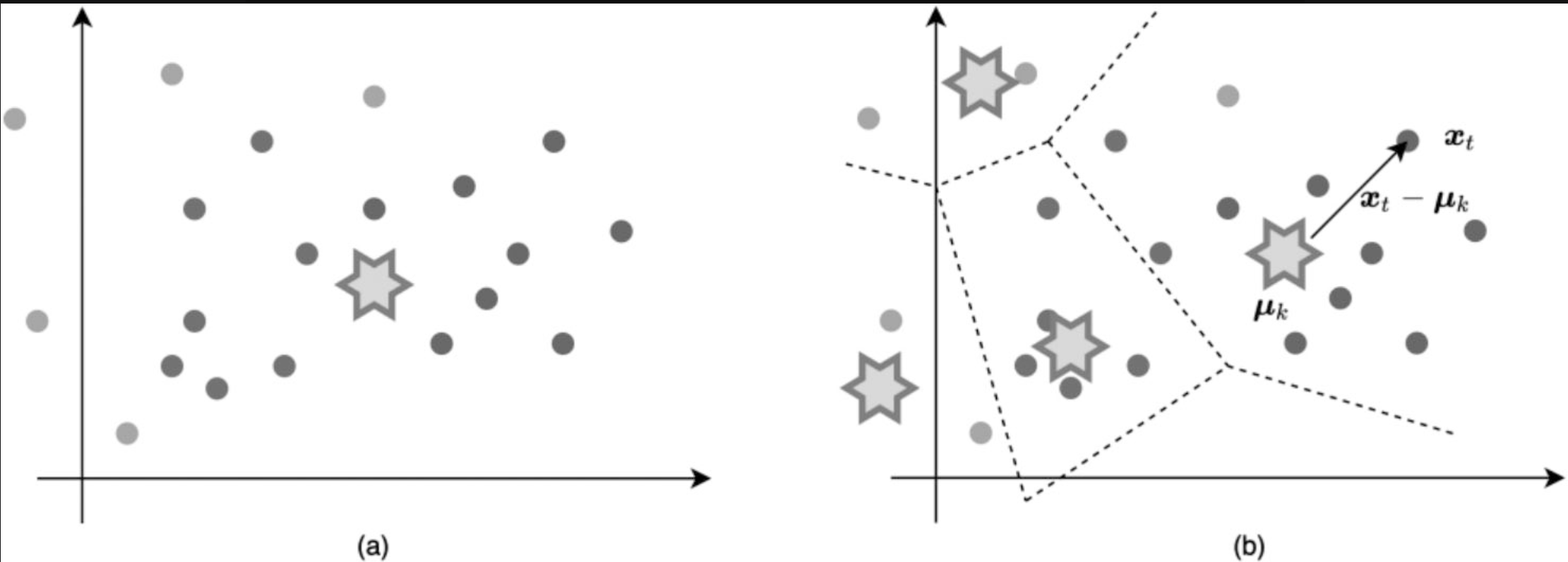
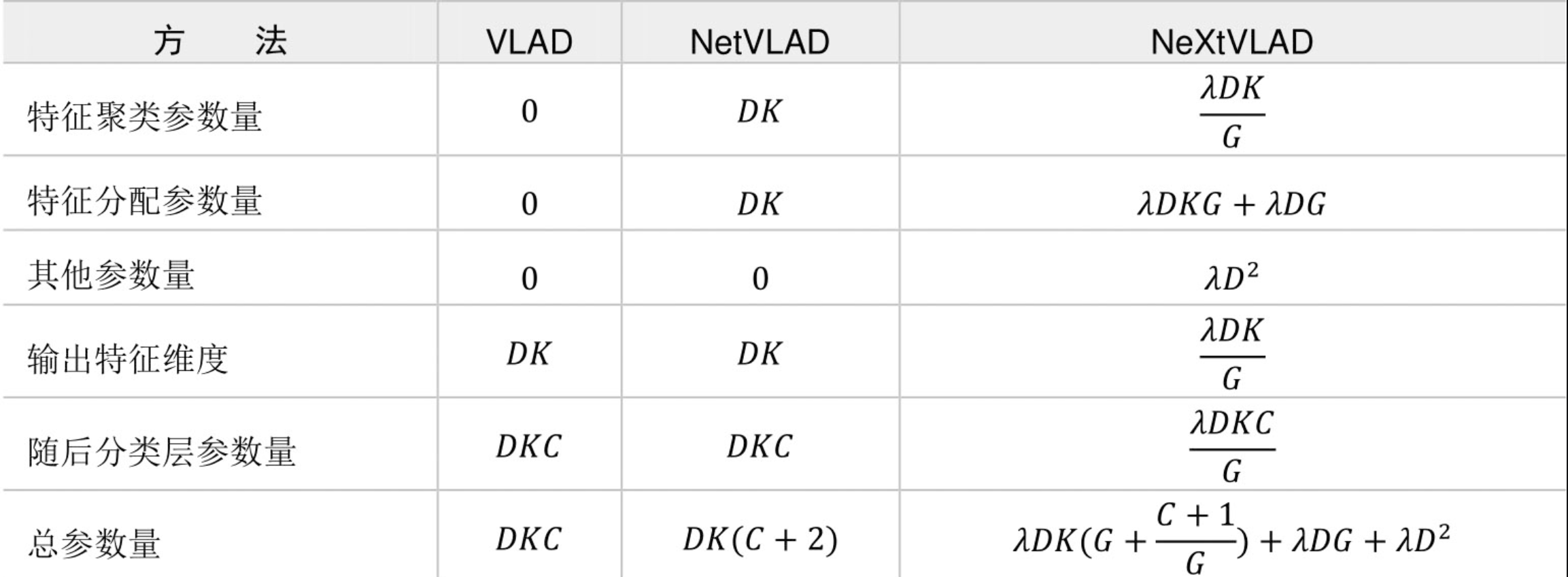
2、VLAD(Vector of Locally Aggregated Descriptors)(Jégou et al.,2010)
先聚类,后对聚类的特征进行拼接
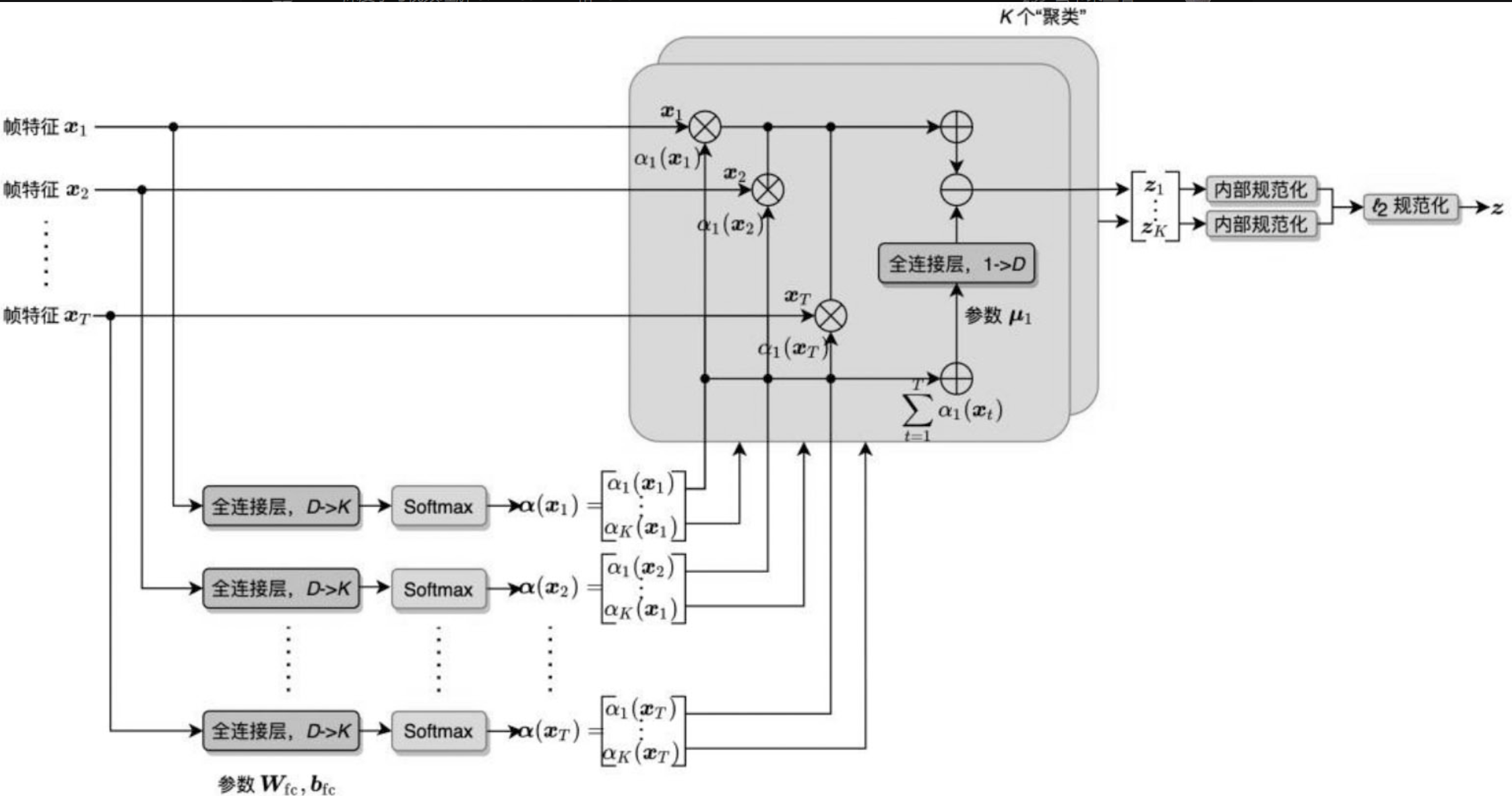
NetVLAD(Arandjelovic et al.,2016)
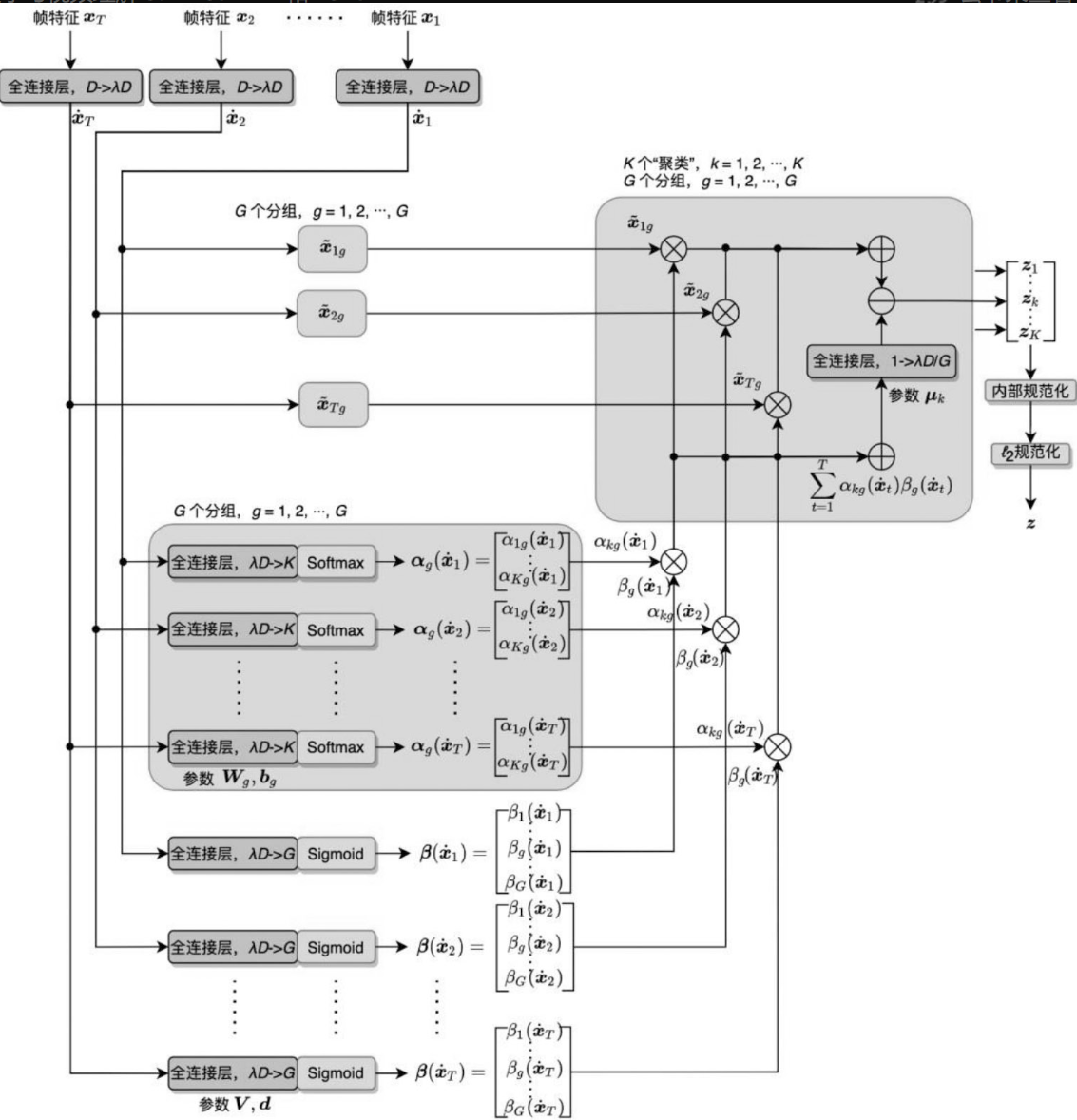
NeXtVLAD(Lin et al.,2018a)
3、RNN特征融合
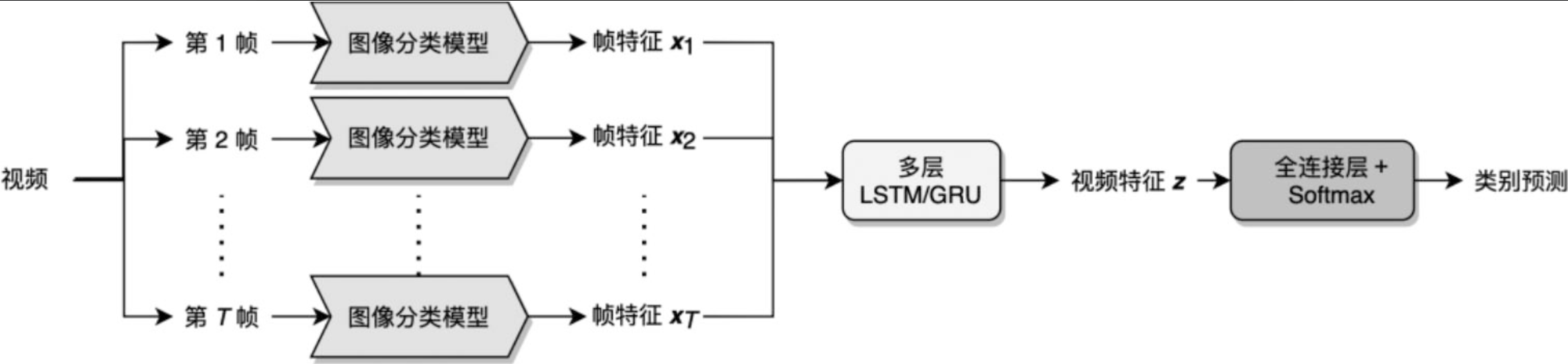
RNN(Recurrent Neural Networks,循环神经网络)有很强的时序建模能力,可以显式地考虑帧之间的时序关系
Fast-Forward 网络结构图
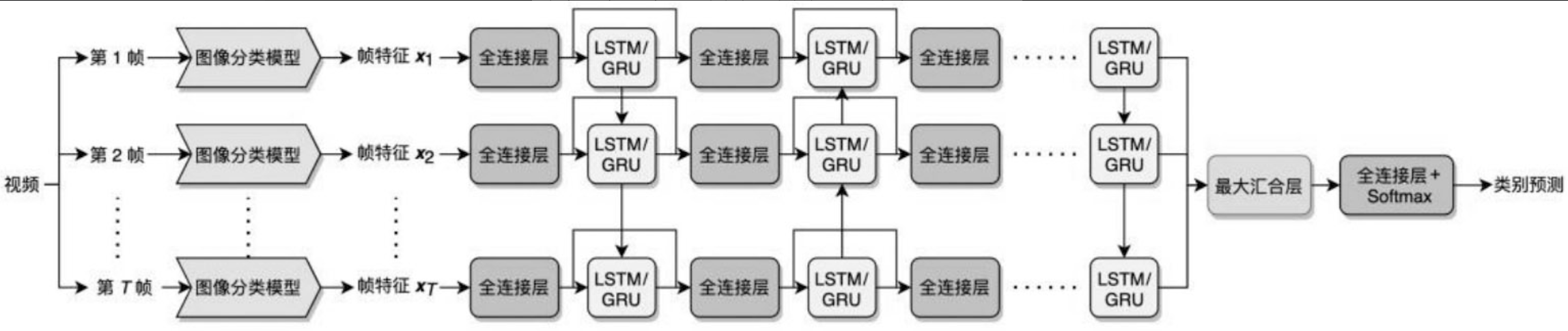
将特征分成两个部分,一部分用图像分类模型提取特征,另一部分用LSTM/GRU捕获各帧之间的时序关系。
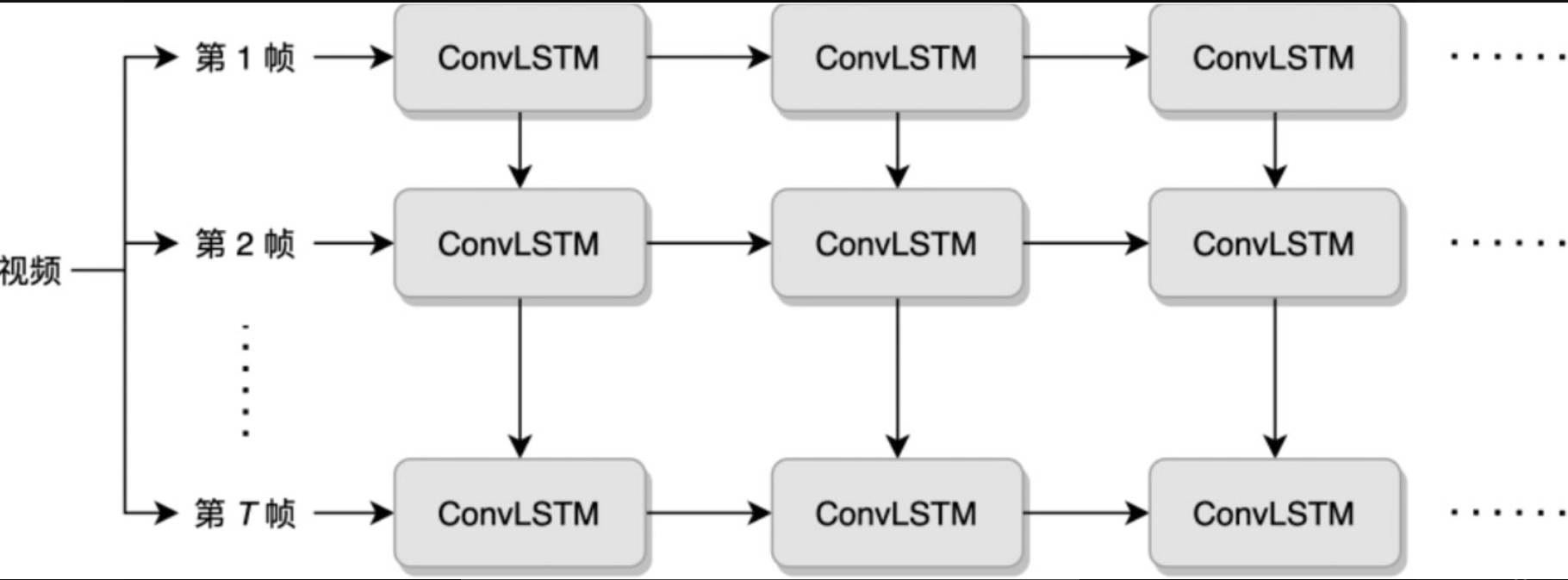
ConvLSTM(Convolutional LSTM,卷积LSTM)(Shi et al.,2015)对LSTM的结构进行改造,将LSTM内的计算由矩阵乘法改为卷积运算,将卷积操作和LSTM合二为一
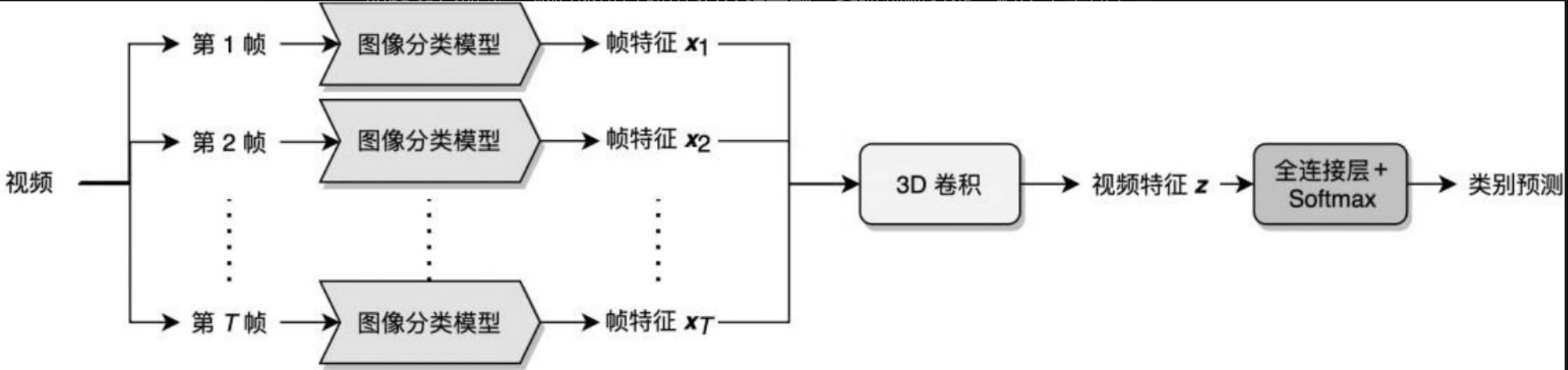
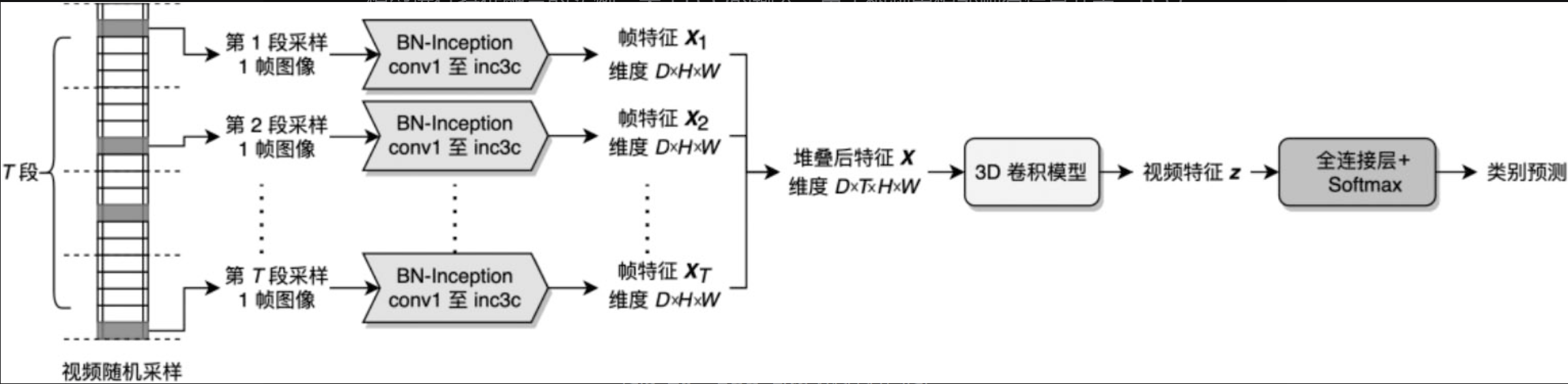
3.4 3D卷积特征融合
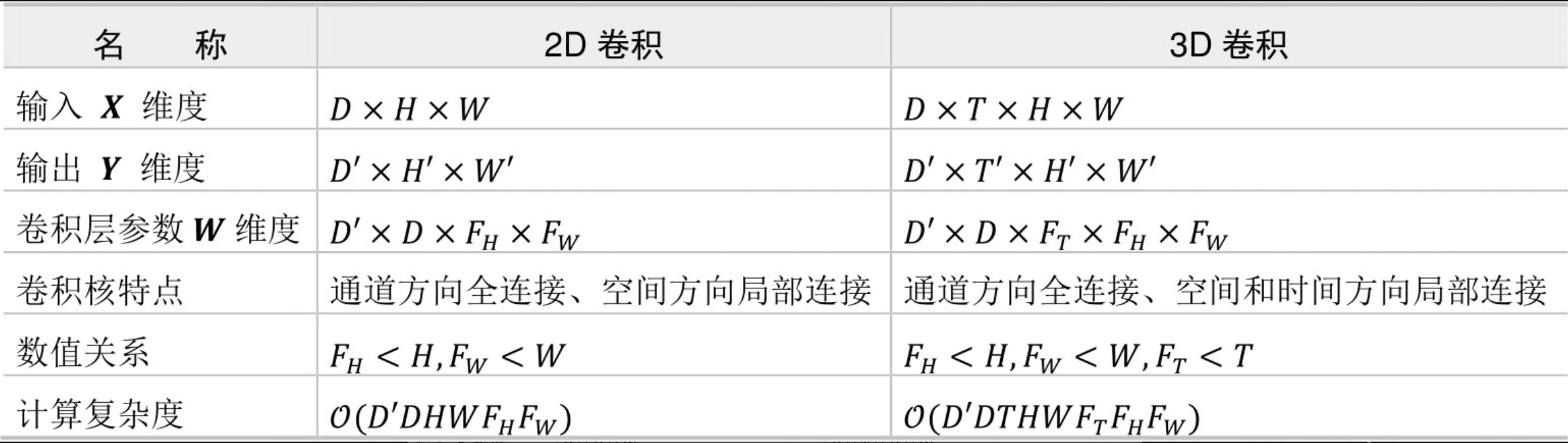
对卷积层进行改造,把2D特征转化为3D特征
3.5、ECO
(Efficient COnvolution network,高效卷积网络)(Zolfaghari et al.,2018)
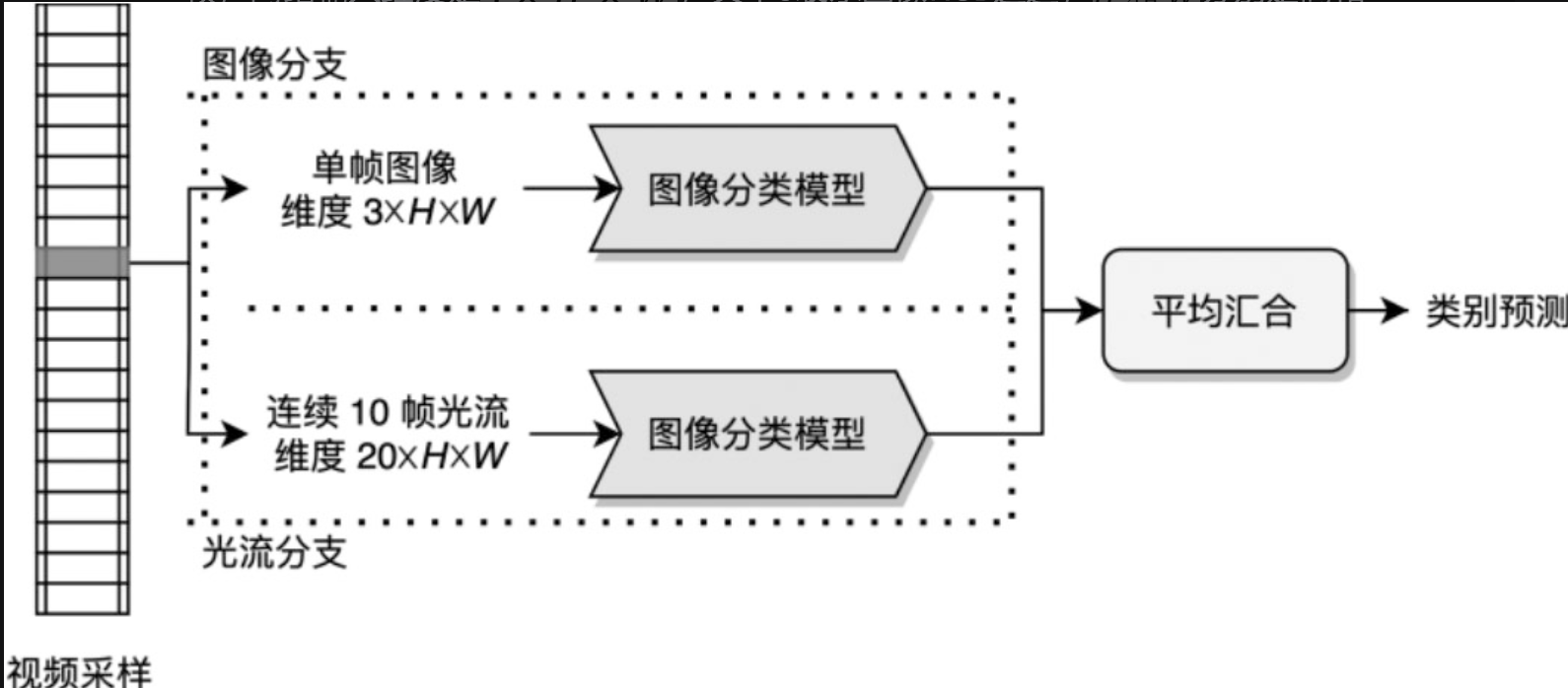
3.6 双流法
可以从视频帧中计算光流,而光流反映了视频帧中人物的运动情况
3.7 时序稀疏采样
更高效地从视频中采样图像帧
TSN(Temporal Segment Networks,时序分段网络)(Wang et al.,2019)
TRN(Temporal Relation Network,时序关系网络)(Zhou et al.,2018)
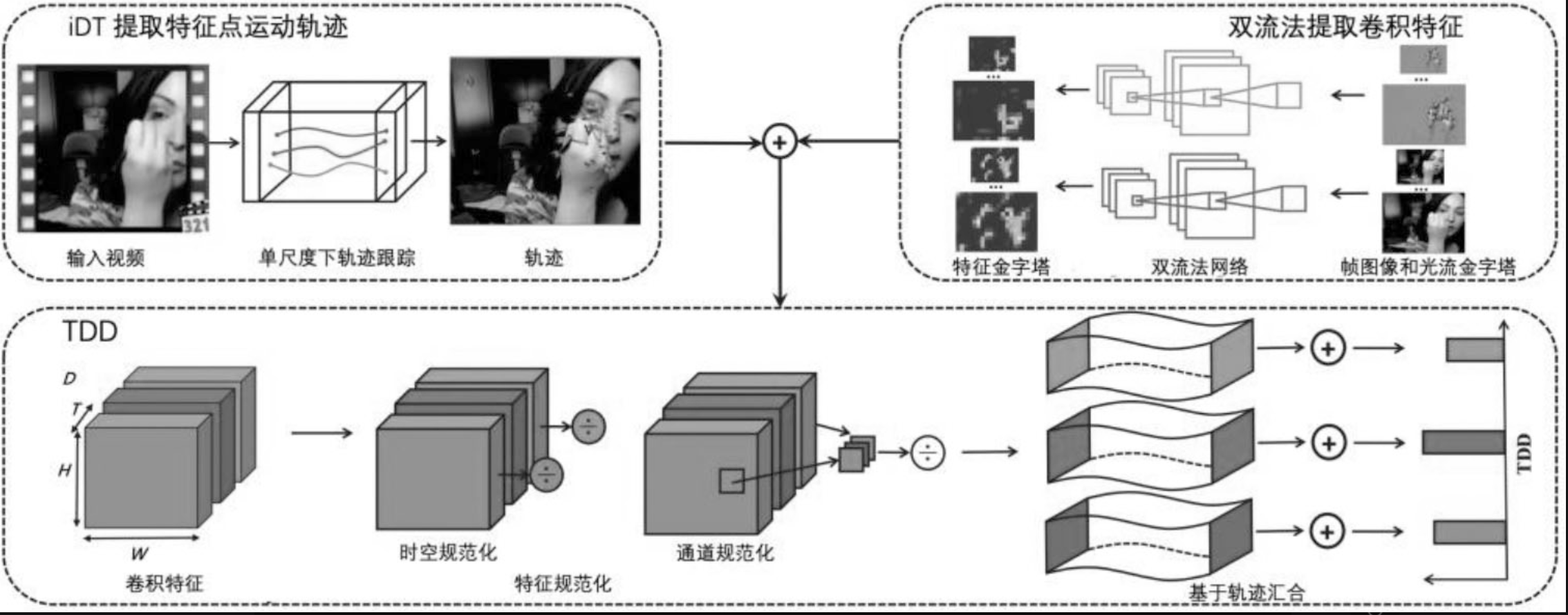
3.8 IDT轨迹利用
DT和iDT可以借助光流得到图像中特征点沿着时间的运动轨迹,之后可以沿着运动轨迹进行特征提取
3.9 TDD
TDD同时结合了两种传统算法(iDT和光流)和深度学习算法(基于光流的双流法)的优点
汇总